I thought I’d give it a go, that’s all…
You might recall (probably not, why would you) that I improved code execution speeds by changing some comparisons somewhere in the rules matching process in favor of matrices multiplications.
And heck, isn’t that what a GPU does best?
Well… Not quite.
First get it to work
It took more than I’d like to admit, but I did make it work (so far, tested on Apple’s ARM M architecture only… But coded to support CUDA, too, I just faced some issues and didn’t get around to test it there…).
So yes, it “works”.
But then comes the question, does it serve any purpose, really?
What changed, so we’re aligned
I “just” check for torch IF the user (… You, my dear reader) decide to use a new parameter in the supervised learning training phase, aptly named: use_gpu (T/F).
IF you decide to use that flag, I then try to check your setup for the {torch} package. That’s my choice, it’s just a choice, feel free to disagree, I just wanted to test the idea…
Then in code I need to check for the flag in several places, a real bother mind you, it made everything less clean to follow (and it was already a bit of a mess).
Mixing {foreach}/{dopar} & {torch}, I get the perfect combo of crazyness, alternative runs possibilities… Not fun, but at least i try to leverage your hardware…
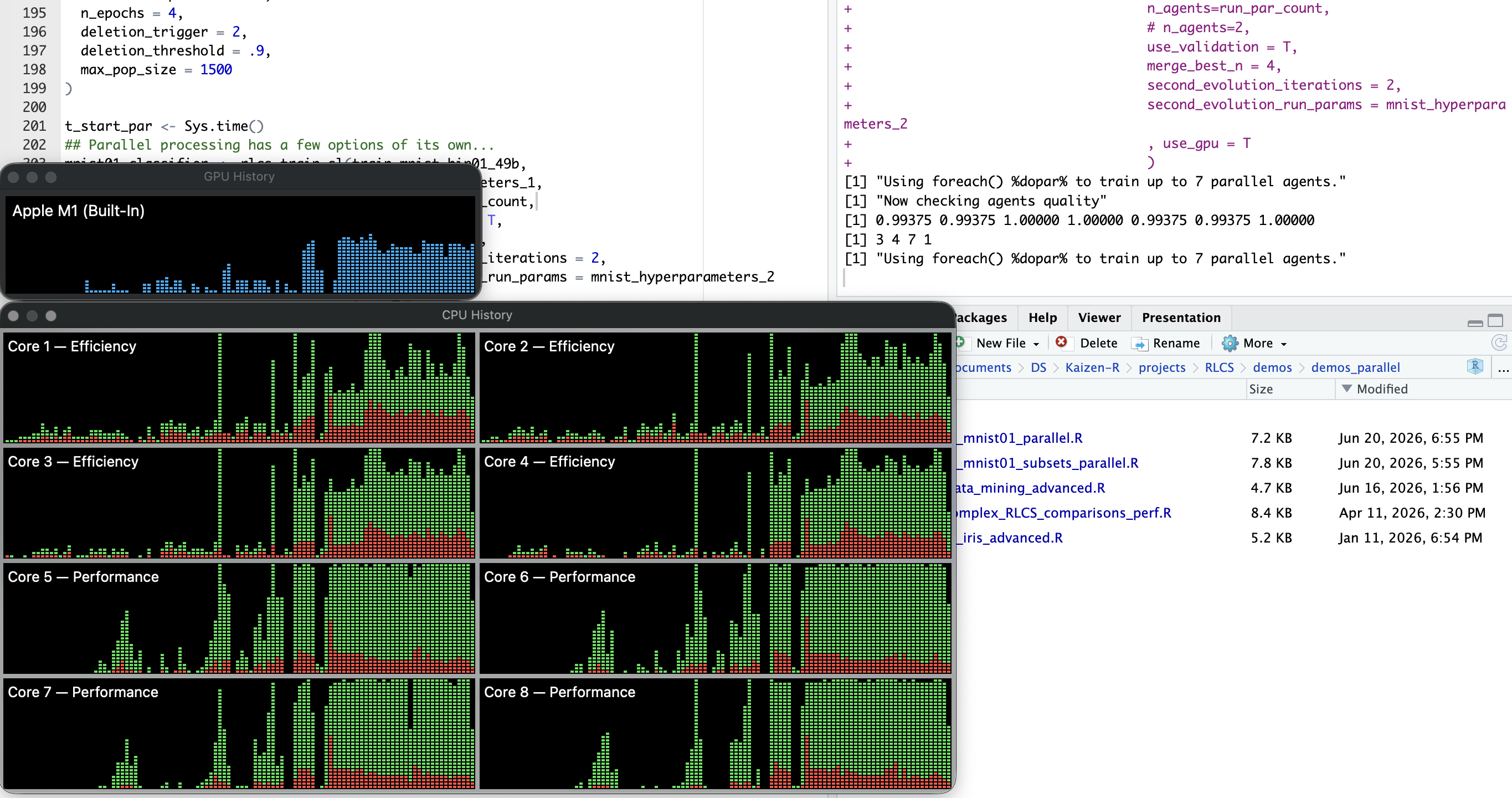
So then it works, but it’s bad
Right so, I mentioned “I multiply matrices”, and in my (rather inexperienced with GPUs) mind, that means “cool let’s use the GPUs!”.
But of course, that’s simplistic.
See a few things happen:
copying of data to the GPU. Now I thought, at least on my MacBook Air M1, that would be marginally worse, as supposedly CPU and GPU share the memory on the SoC. Apparently, lucky me, it does, but it actually gets better with M2 and onward… I purposefully avoid buying new hardware for now (waiting for M6, hopefully, the 2nm transistor thing…), so of course on M1 it’s well, not great…
But clearly soooo much more relevant: copying back a forth onto the GPU is bad, but using a GPU to simply multiply one (or maybe a few) rather not gigantic (what, 50*5000) matrices with small (50) vectors… That’s almost idiotic, apparently. It turns out, my assumption was incomplete at best: yes, GPUs are great to multiply matrices, but only if you multiply very large matrices or do many parallel matrices operations!!!!
So, this has been thus far a rather loss of time, aside from my new learning on the topic (which, it just so happens, to me is just as important as the results!).
If you want numbers, one exercise was quite literally twice as slow with multi-CPU+GPU, vs multi-CPU…
(shrug)
Next steps
I could simply scrap the whole GPU support thing. But you know what? NO!
See, now I have yet another motivation to try to parallelise more matrices operations, and/or make these larger.
So this actually gives me some ideas:
Can I do parallel matching of environment samples? Would that help? That would mean I could check several (all?) samples in a Supervised Learning setup, and then I could probably see what to do about covering.
For larger problems (e.g. more variables, or larger environments), using the multi-core (CPU) setup might actually be helpful to leverage multiple parallel GPU operations somehow.
Maybe mixing the above two points, I can try to make a difference for the larger & slower exercises, which, well, is all the point anyway.
Conclusions
This took, in the end, the best part of a Sunday afternoon and a Saturday afternoon (yes, an LLM would have been faster, but I DO NOT CARE!).
However, I finish the exercise (for now) on a positive note: It works, I know why it’s not helping with runtimes, and I have hints about where it might actually make a difference some day.
On the negative side: Well, it kinda failed, as in things on M1 are in fact (quite a bit) slower than with pure CPU, and it shows I have a lot left to learn about GPU and their use…
Then again: Learning is a net positive… So in spite of the poor “results”, I’m actually quite happy!