Up until now…
I have had an RL agent (or several) moving around in a simulated World for quite some time now.
For RL, you have to choose somehow when to explore, and when to exploit. Up until now, I simply would train with more exploration first, and every 2000 steps or so, I would reduce the pressure to explore (i.e. augment the exploitation). I would start exploring every 2 moves, then every 3, then every 4… And so on until 1/10 moves.
Today I worked on an alternative.
In reading about RL in context of intelligence evolution, the “more intelligent” beings would somehow learn when to explore, and when to exploit, to their advantage.
In a static World, once you learn the basics, you would have no reason to learn further, you would exploit. Maybe, though, you’re missing on better alternatives which is why one would still explore sometimes.
I choose today to supplement my agents with a sense of hunger.
Steps towards “hunger motivation”
First, I “warm up” the agent for 2000 steps. That’s just so they have a minimum “intelligence”.
Next up:
When hungry (“internal status” is below a threshold), the agent explores say one-in-10 moves.
Then, if the agent is well fed but inexperienced, I force it to explore more than if hungry. One-in-3 moves. This might return it to the state of hungry and the agent will oscillate accordingly around that.
If however the agent somehow learns enough to accumulate enough food to pass another high threshold, where the agent is well fed and experienced, I suddenly reduce the exploring pressure, to 1-in-30. That’s the status of seniority, if you will.
What’s cool about this?
Well, first, the mechanism described above (which I call mechanism 2) for some reason appears to help in fact the agent become much better than with the original (mechanism 1). Check out the proportion of food, empty cells and enemies, below, with mechanism 1, and then 2, both trained with the same rules of the game:
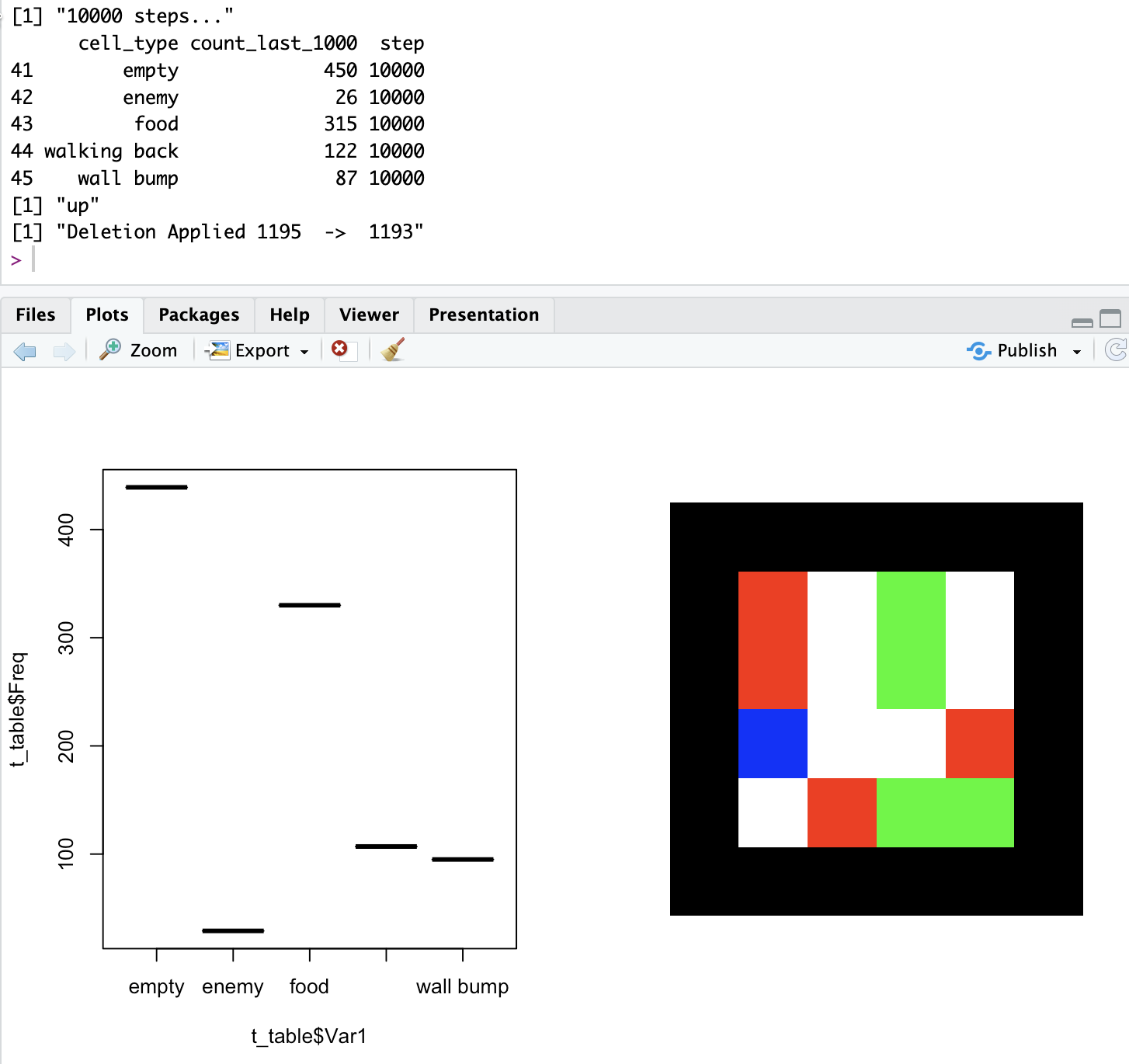
Here goes the new results with the new approach:
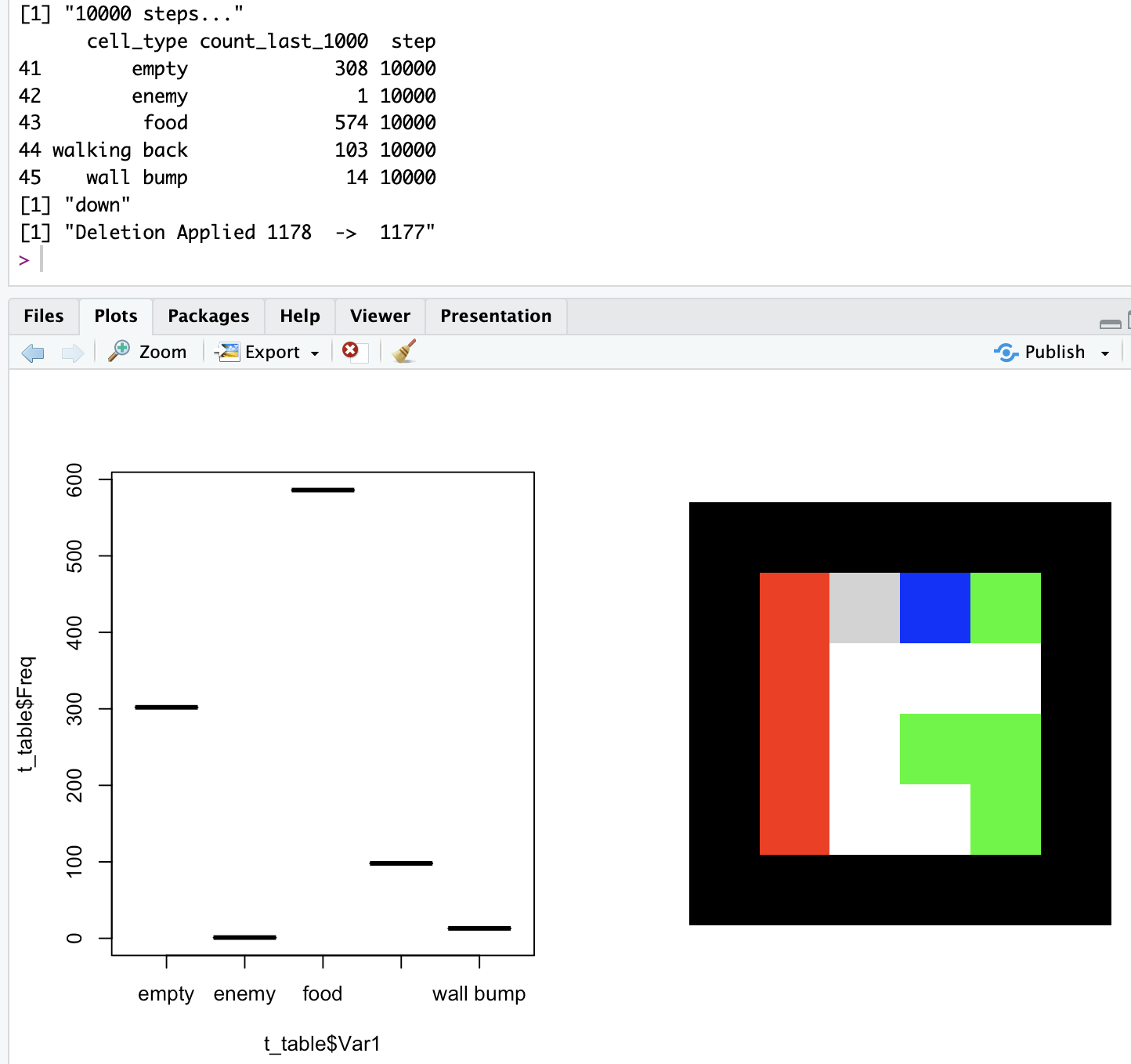
What’s even cooler?
This might never happen, BUT what if I coded a world where the rules suddenly changed?
Now this is potentially very nice: The original mechanism 1 would not react, no change in behaviour.
But mechanism 2, when the exploit strategy starts to fail, would jump back to exploration! And depending on how much it has created a habit, it would resist more or less the switching back to learning…
Also
Some more of the code for Reinforcement Learning is included in the published package for RLCS. However as it is still imperfect, and rather complex, I keep it “hidden” by default.
Bonus: Video
Conclusions
Well, just an interesting exercise really. RL, in this case with simple reward-shaping, per-se has no “motivation to explore further”.
I just implemented this as an idea inspired from animals, that can (here the comparison):
choose to explore more and take more risks if not hungry
choose to exploit more if confident they have enough experience
revert to exploring in case the world around them changes
At least, this is what the parameters I used pretend to express. And the fact is, it appears to be an improvement on the basic RL setup I had.