You’ve gotta love it when ideas work out…
Matrices multiplications instead of char-by-char string comparison for matching: From 30s to <1s. GOSH! I just eliminated the biggest bottleneck!
Yesterday’s idea: Today’s results!
I mentioned it in yesterday’s post. Well… Now it’s a reality. I just updated the GitHub accordingly.
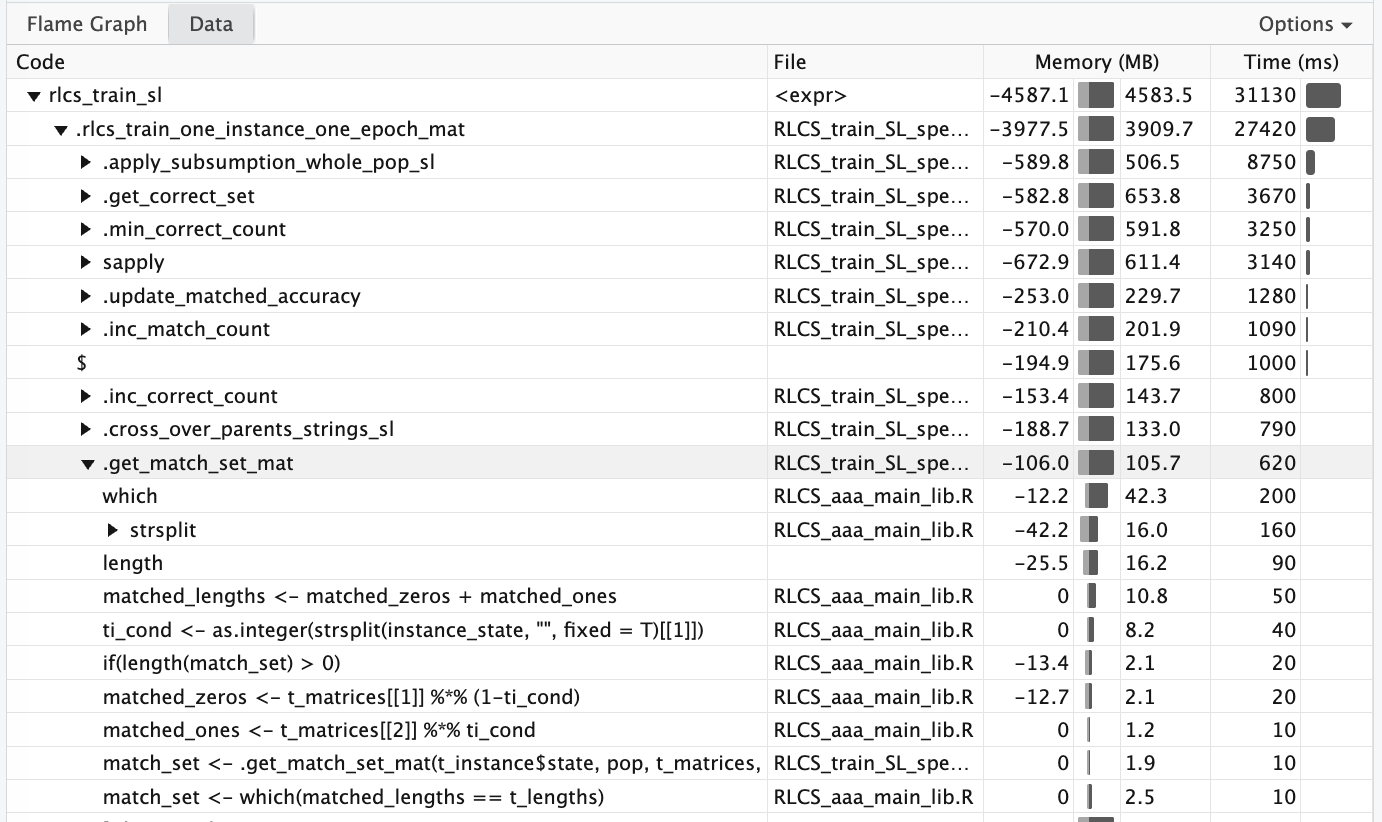
I’m not proud of “how” I coded it, mind you, but it is working, and also, it’s fast. I’ll make it cleaner in upcoming days.
Also, as matching was the key step in “prediction”, well predictions are almost instantaneous too, now!
Memo-ization of sorts
So on top of the matrices multiplications approach, which is naturally faster than strings matching the old way, I now keep track of the whole population “match matrices” for where a zero is found per rule, and where a 1.
Keeping it updated ONLY when I CHANGE the population (addition or deletion of rules), separated from the other steps, also ensures matching is now “just” matrix multiplication, no more.
Again: I don’t know if “clever”, but… What a difference!
Edit: Getting even better!
The above was… This morning. Instead of a new post, I’ll just edit this for “tonight’s edition”.
The next bottleneck was: Subsumption. But I could use the same matrix approach to reduce iterations!
And I did, and here what it looks like (see how it changes from the above?):
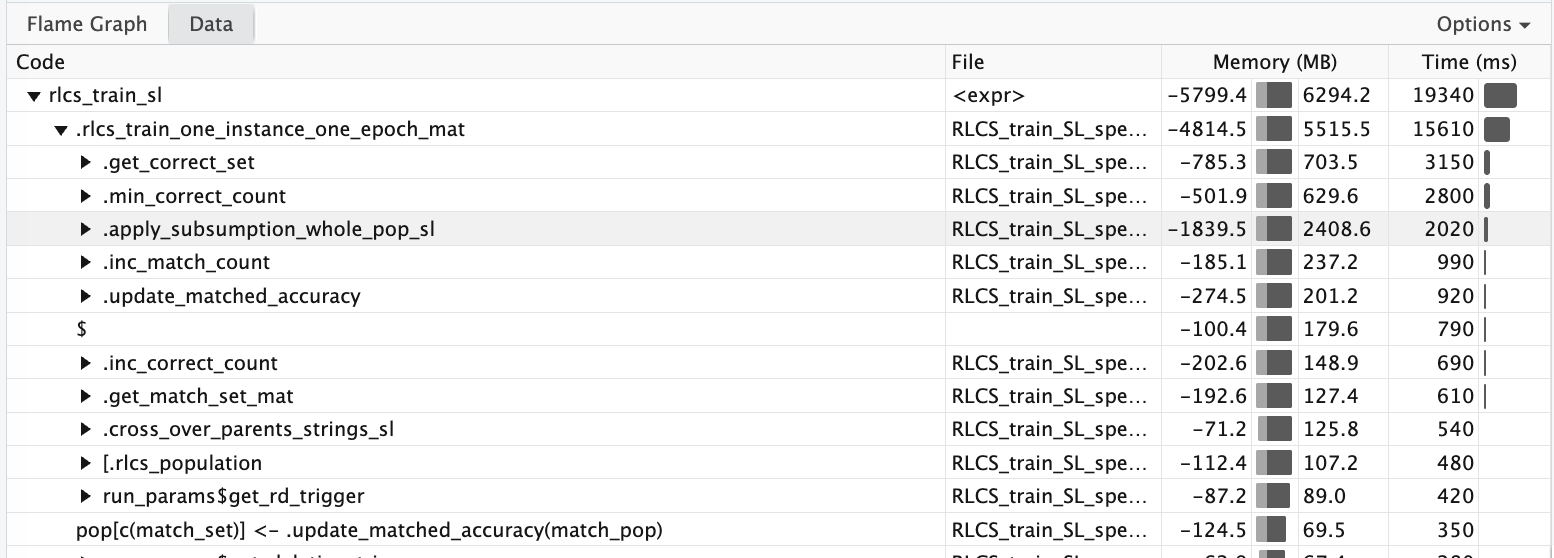
So what? Well…
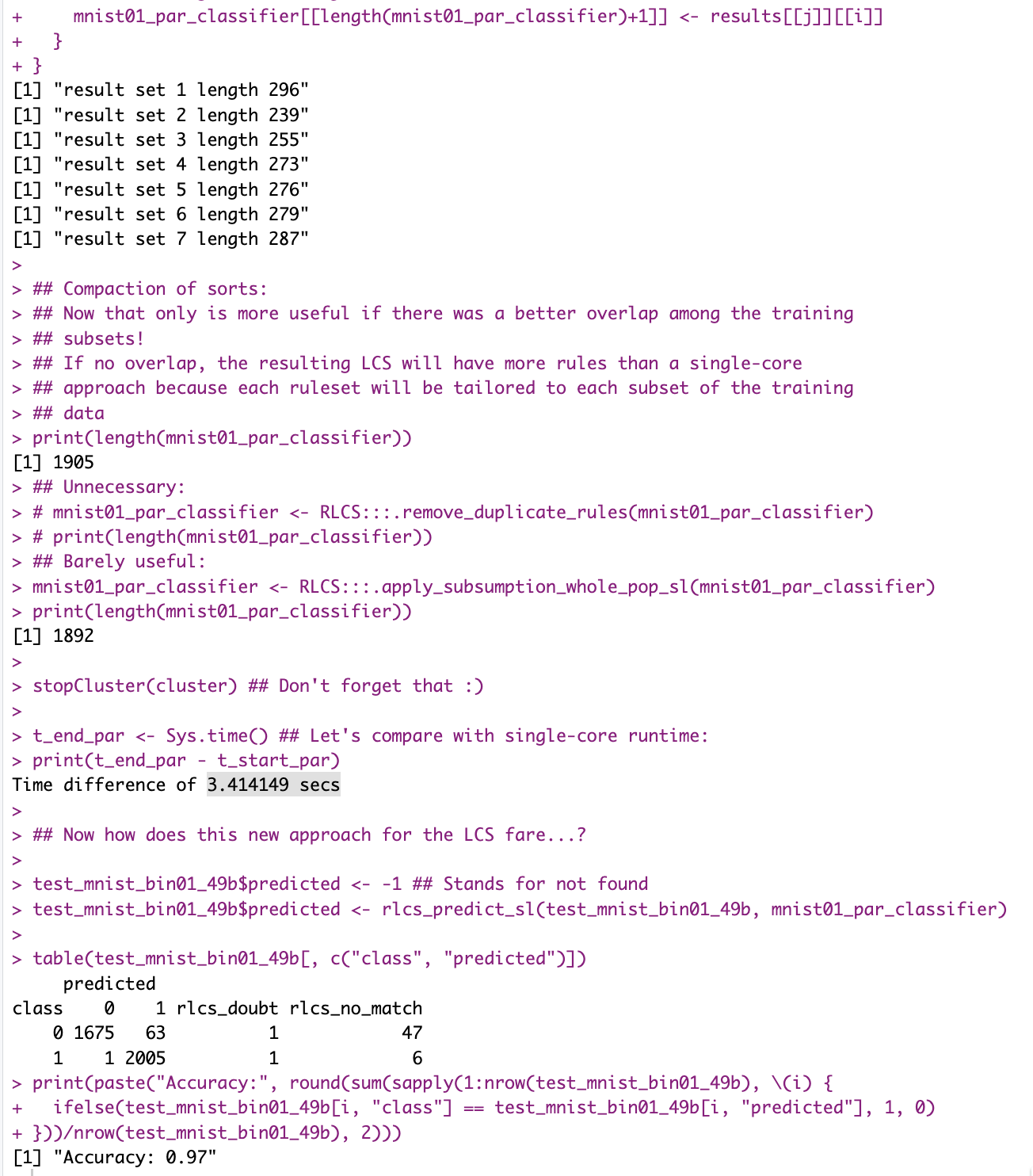
If I use all my tricks, I can train a “good” (97% accuracy) images classifier in under 4 seconds.
And if say you don’t have multi-core/multi-thread, even then… Processing time went down from 1m20s to 28s, and accuracy (with less cheating) is even better (99%):
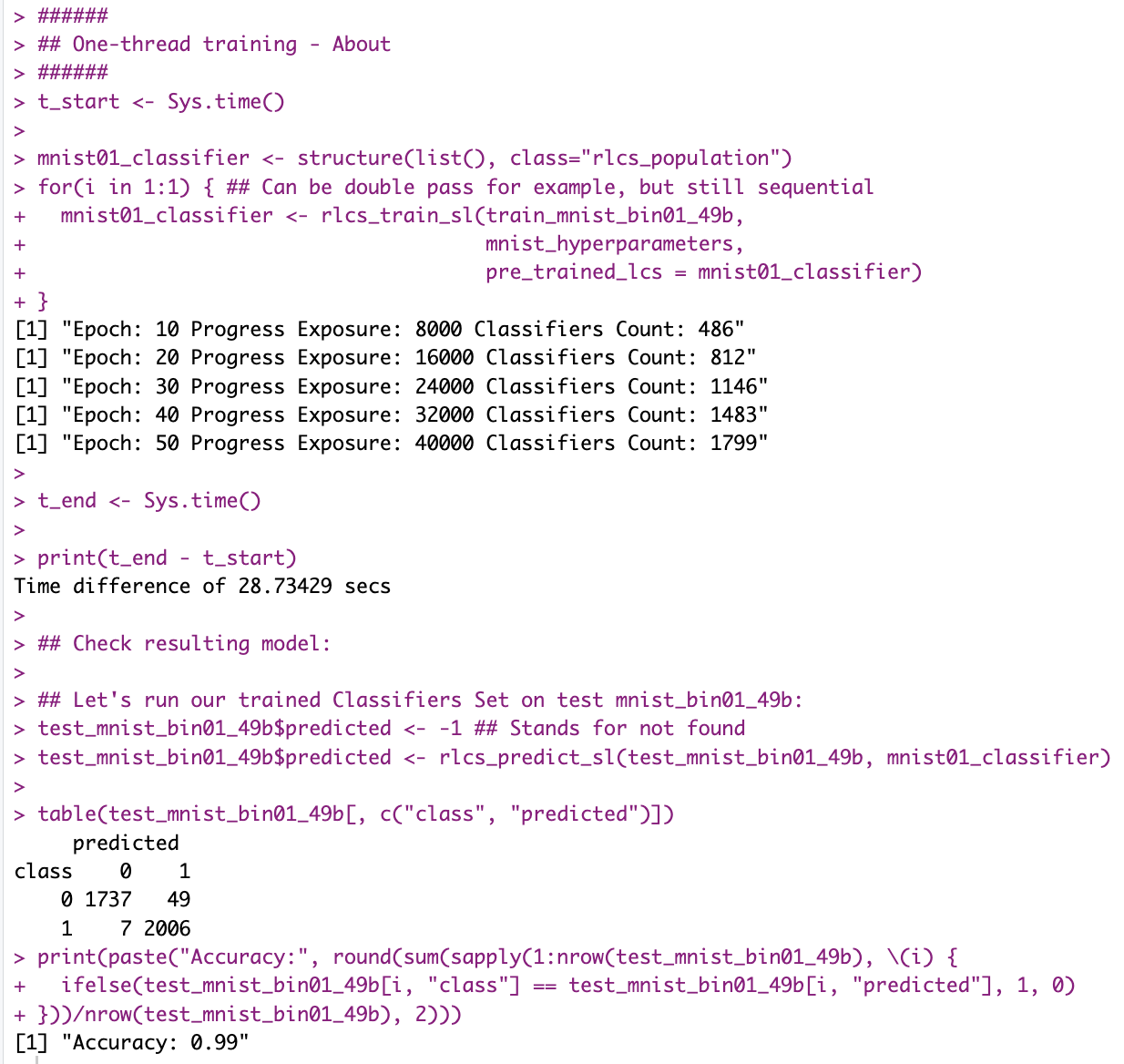
And all that, with lots of compression (and information loss) on input, and training on 800 samples (for testing on 3500+!).
I still can’t seem to beat Random Forest on the Iris dataset for whatever reason, but all this will help for sure, and I have a feeling it somehow can be done…
Conclusions
How many hours have I spent testing long-running stuff… That could have been much much much faster?
Anyhow…
The code was adapted “quick-&-dirty”, so I’ll need to refactor it all (quite a bit). Right now, I’m skipping passing variables among fonctions and updating “parent envs”, which, well, I don’t think is a good practice at all. Unless I control exactly what I do, I guess…
But the point stands! I just essentially eliminated the bottleneck. Not “reduced”, no no no. Eliminated. This opens a host of new ideas to consider: Longer matching epochs (i.e. reduced triggering of subsumption), for one!
This is a great leap forward for RLCS!