I said it without checking…
OK so I just wrote that “RLCS is more like RF than Partitioning Trees in terms of classification power in SL settings”.
But that was bold! I actually just meant that it is also an ensemble learning model of sort.
But since I was at it… Why not check the assertion?
Well!
Alright, I’ve explained how I go about the Iris dataset with RLCS a few times now. One key aspect maybe is that in encoding states, I do loose precision of the input. (e.g. I force some data loss). That is, in the current state of affairs with the Rosetta Stone.
I just ran a randomForest model against the Iris dataset too, now, because I wanted to see how much I was lying…
Here the code: I tuned nothing, it’s kind-of-defaults here:
## Running demo_sl_iris.R first to select train_set/test_set, then come here:
library(randomForest)
iris_rf <- randomForest(Species~.,data=iris[train_set,],ntree=100,proximity=TRUE)
print(iris_rf)
irisPred <- predict(iris_rf, newdata=iris[-train_set,])
table(irisPred, iris[-train_set,]$Species)
## Results in Accuracy:
25/30Here the FIRST results ever of such a check by yours truly:
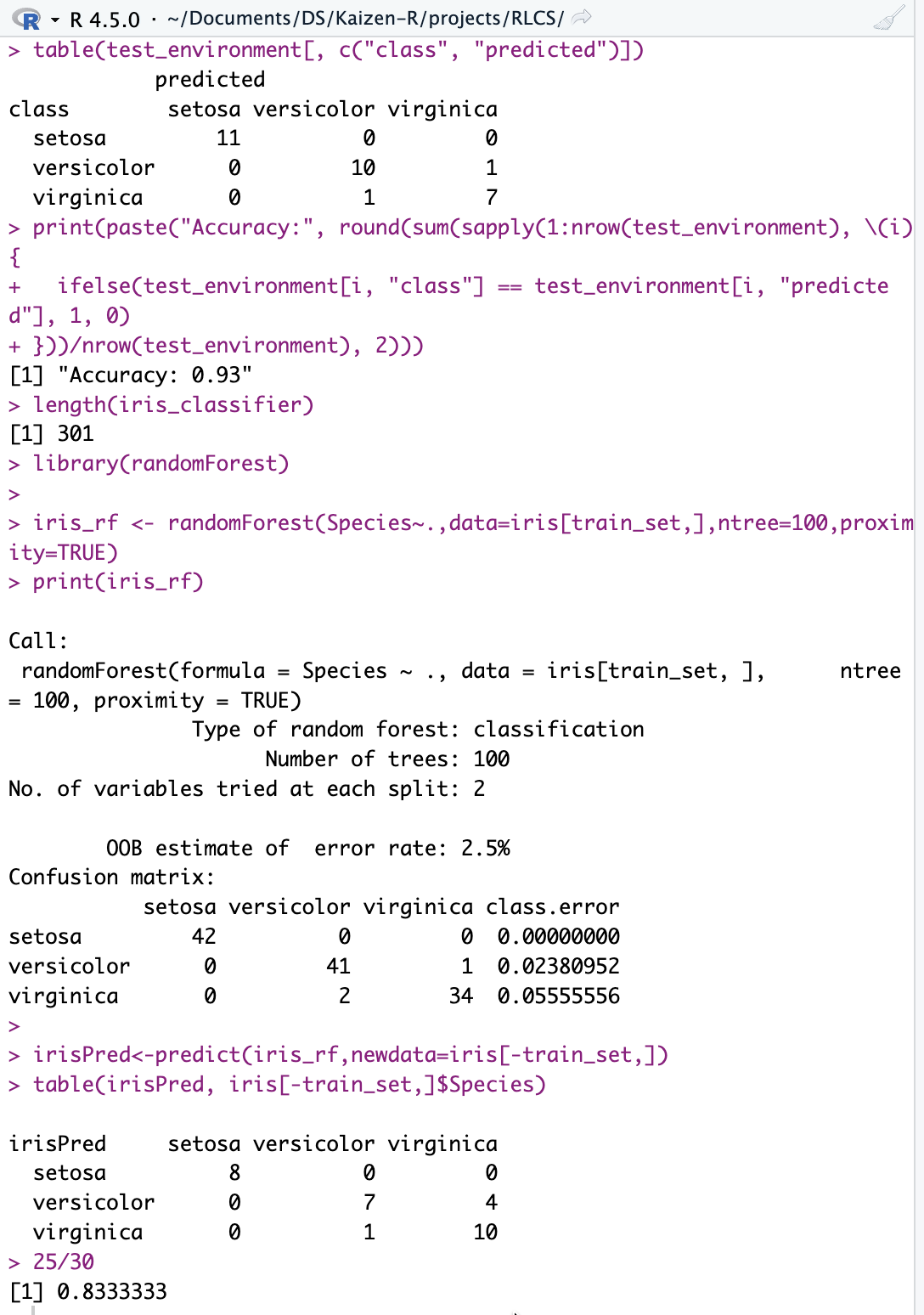
10% better Accuracy! (and it’s on the first test ever)
Yes but!
This is also unfair, because I fixed a seed to run RLCS, which is stochastic in nature. I just took the one in the demos already included on my GitHub.
A truly valid test would be to run it a few times and average accuracy, for one.
So, believe me or not: I just changed the seed, and RLCS gave back a 97% accuracy. Try it: change the seed in the demo for Iris to 1234…
BUT the moment I did that, the Random Forest gave back a 100%!
Also, I haven’t thought even a minute about the RF hyperparameters, I’m sure it can be improved. If you throw in a few more trees, maybe…
I’m just saying, it’s a first test, I haven’t done anything special, this was a FIRST RUN result, which had me euphoric for just a moment. That is, until I ran a second test :D
Since then, I also ran an rpart with the exact same results than random forest (facepalm).
Which is to say: By pure dumb luck, and without tuning anything specially, RLCS was better for a given seed, and worse overall for the few other seeds I have tested, than RF.
Too bold, I was. Fair enough.
Yes, it’s also much slower indeed
No questions asked: RLCS as it is today is not fast. And yet: If it was better in the results, and it’s more interpretable, it would be more of a price to pay for the trade-off.
Conclusions
This one was a first, quick check to assert my own conceptual ideas in comparing RLCS to Random Forest.
You should know: I like RF. And RPART. Better than Deep Learning, if anything. But yeah, RLCS is not quite “there yet”.
Now I am also aware this was an imperfect validation (to say the least).
Anyhow: I need to run many (many) more checks and see what’s what. New question:
Can RLCS actually be better for certain scenarios? Or is it slower and also worse at classifying than RF?
Unrelated: This is all “post-Spanish-R-congress” whereby I was given the chance to present RLCS to the R community more “live” with a 15’ communication. (The time pressure was a big deal, but I hope I managed to transmit something.)