Rcpp did its part, but…
There was still room for improvement. Probably still is, of course, just… Not with a total redo, I guess.
There were two or 3 key ingredients to the improvements.
Daring with fewer epochs (and I found out eventually, I really didn’t need hundreds or thousands in some cases, so I’ve been waiting during many tests for overall probably quite a few hours that could have been minutes, had I tried better combinations of hyperparameters!)
Just so we’re clear: With the Rcpp trick last week, now working on my Mac (Macbook Air M1), and quite a few basic improvements (unnecessary iterations here and there (shame on me), particularly with subsumption and deletion, faster sorting now without resorting to rbind.fill(lapply()), which is nice, but quite unnecessary, and sorting is key at several moments)…
And (and this is relevant) by using a better set of hyperparameters per use-case…
Overall, we’re talking quite literally about one order of magnitude in performance gain, in some cases.
Not bad!
From 7 minutes to <2 minutes (with bigger training sets)
Quite literally. I had a screenshot of me training with images here.
There it said, basically:
6.9 (~7) minutes. For better results, even 9 minutes. For a training set of 500 samples. That was 2 months ago.
Here is what it is today:
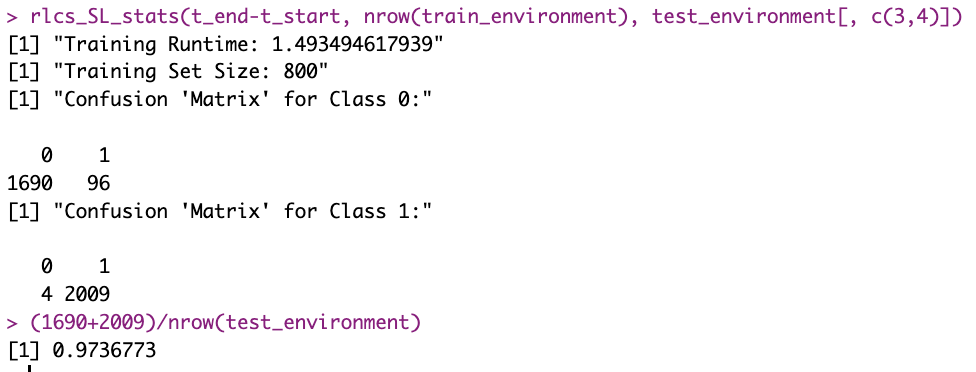
That’s well under one fourth of the runtime, and with 1.6x the data.
From 4 minutes to <3 seconds
Yes. Well, this one is my fault, really.
I THOUGHT (in my head, with no tangible proof) that the “not_bit_4_10” was supposed to be hard for the machine. What with 10-bits strings and all… As it turns out, if you trust the process, it needs not be.
Here is the original runtime for that particular test:
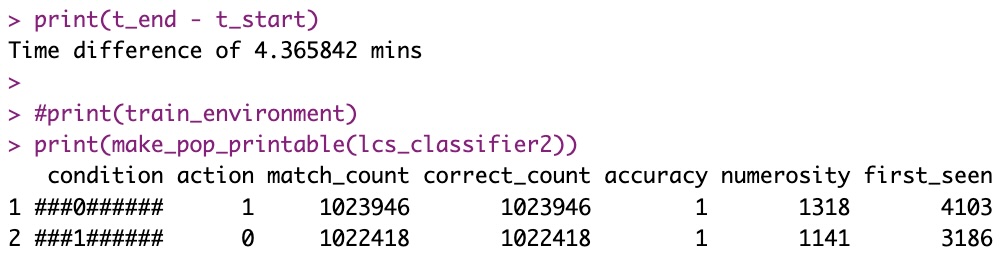
That was bad!
As I’ve been working on performance, here a screenshot of runtime with same perfect resulting classifier today:
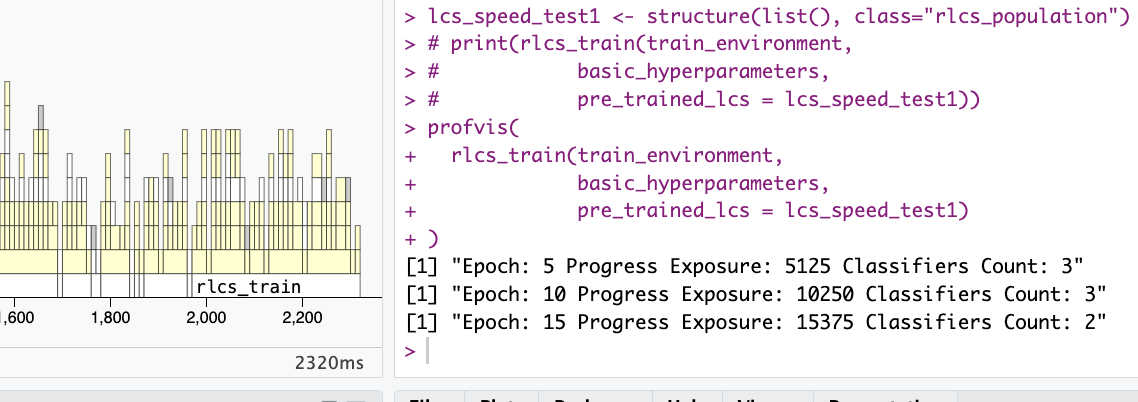
Now, to be fair: Hyperparameters were “optimized” for MUX6, and I was still focusing on functionality more than performance, back then, but now… Well, now it is “bearable” :)
What about iris?
Well, not to worry!
I did myself (and the community) a great disservice by not optimizing this a week ago. During my last presentation (last week), I mentioned it took 3 minutes to train on Iris dataset. What a pity. What poor performance that was, truly…
Here is the update, and I believe it’s significant:

For reference (for myself, to have a sense of where the competition is at), I ran a demo with a Neuralnet. Indeed, that’s like <2 seconds, maybe <1 sec. But it’s probably (my guess) all C.
Plus, we know the LCS algorithm is inherently slow, there are limits to what we can do about it.
Still.
Well, now it’s faster. It takes 3 seconds. 1.7% the time announced a few days back…
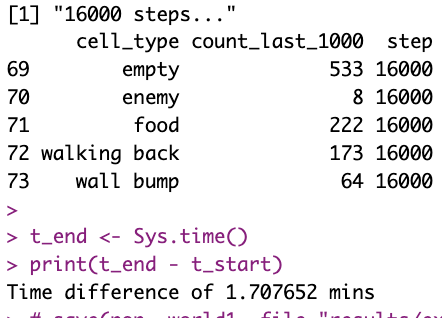
Same for RL!
Training an agent that is reasonably good (remember, it is stochastic, so the thing isn’t always easily comparable), at least from statistics of its last 1000 moves, used to take quite literally 10 minutes.
I’ve gotten under 2m now:
Limits of Rcpp for DoParallel (for now)
So I found one thing that will require more work: %dopar% and Rcpp don’t play nice “out of the box”.
Seems like they will WHEN I make the whole thing into a package.
Even then, parallel training for images classification with 1.6x the original training size, parallelized over 7 cores (M1) and split accordingly (input subsets), gets me similar results without the Rcpp gains as the Rcpp serial version. And the serial Rcpp version is already about > 1.5x as fast as the pure-R version, so…
Maybe we can go even faster (and I don’t know that this particular example was the harder one for justifying parallel computing… Oh well).
So here, another thing I will have to work on.
Conclusions
I don’t know that I’ll be capable of making this much faster by now, lest I review the overall approach with lists for something even better, maybe (data.table?). But that would be for a V3 or something, so not for now.
Right now, it’s not too bad.
Heck, dare I… I’d say it’s actually maybe even quite competitive now, given the readability of the output model.