GA Implemented, and full discovery works!
Intro
I have yet another day off (that’s the thing with Holiday season), and I really wanted to keep working on this.
So I added the Genetic Algorithm part to my Supervised Learning basic Michigan-style LCS.
That means, after covering (done last Sunday) I am done with the (basic) implementation of the Rule Discovery features of the LCS algorithm.
And, heck, it works.
What the GA does
So we had covering, whereby new rules were created when none in the classifiers matched the a new-coming environment instance.
But this is only part of the discovery of new rules. The second part in the Michigan-style LCS is that of a Genetic Algorithm.
I implemented now a simple version, with tournament parents selection. That is, from the Correct set (see past entries) – but taking numerosity of classifiers into account – I choose N (a parameter) parents randomly. Then I take the best 2 parents by fitness. Which is ellitist.
Then I run a one-point cross-over, to generate 2 children.
I apply mutation to the children genes in turn, with a mutation pressure set as yet another parameter (default is 5% in my implementation).
And finally I add the children to the population.
Note that children mutations ensure only valid rules are created (i.e. condition is compatible with the training instance). Mutations either generalize (add a wildcard) or specify (replaces a wildcard by a 0 or 1, depending on training instance).
Fully general (“all wildcard”) individuals are of course discarded. If a child actually matches by condition an individual in the correct set, it is discarded and the repeated classifier instead get a numerosity increase.
And that’s IT!
Results with fully functional Rule Discovery
In my current dummy example, whereby the goal is for the LCS to discover the rule “Class is NOT(bit 4 of input state)”, well… In manual runs (several of them), I often (not always, mind you) find the two best rules are perfect rules:
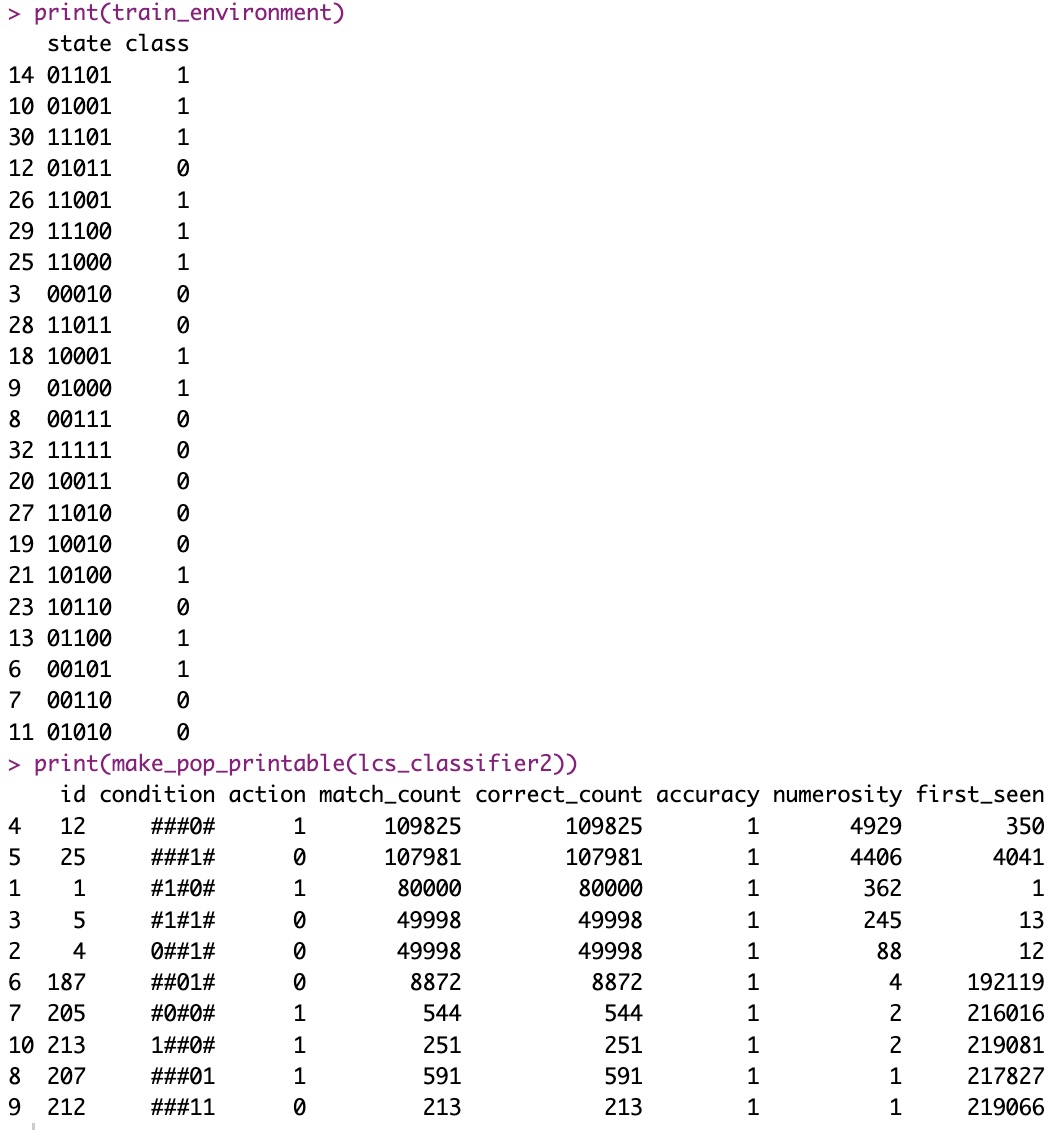
IMPORTANT: What the rules set tells us!!
The first two rules (ordered by accuracy and numerosity, both decreasing) are the exact rules that perfectly will always predict the correct class/action, and are perfectly balanced in this case between general and specific.
These are the kind of things that an LCS provides that a Neural Network won’t:
It tells you WHY it makes a decision.
Here, it is saying:
Rule 1: If bit 4 is 0, then class is 1. I am 100% accurate, whenever that happens.
Rule 2: If bit 4 is 1, then class is 0. I am 100% accurate, whenever that happens.
Which is exactly what this dummy training data set was trying to say in the first place, with 70% of the training possibilities shown to train the algorithm.
Obviously this is… A somewhat silly example. But the thing is, I did NOT tell it how to get there, and it got the IF THEN ELSE correctly on its own.
DELETION is also implemented
Every now and then (after a certain number of Epochs) I run a Deletion process, whereby rules that have Numerosity 1 are discarded, thereby containing the size of the set of classifiers.
This is important for interpretability and performance.
Conclusion
I am quite happy that after only a couple of days of coding, I have a basic, perfectly functional LCS!
I do miss two components: Subsumption and Compaction.
Plus of course the Prediction, that comes after training, on a test subset.
It’s all on my to-do, but this thing is already promising!
Granted, it’s not real fast. And the code is far from perfect, or duly organized. But it works!