RLCS: A (shorter) Introduction
Interpretable, Symbolic Machine Learning
A new R package

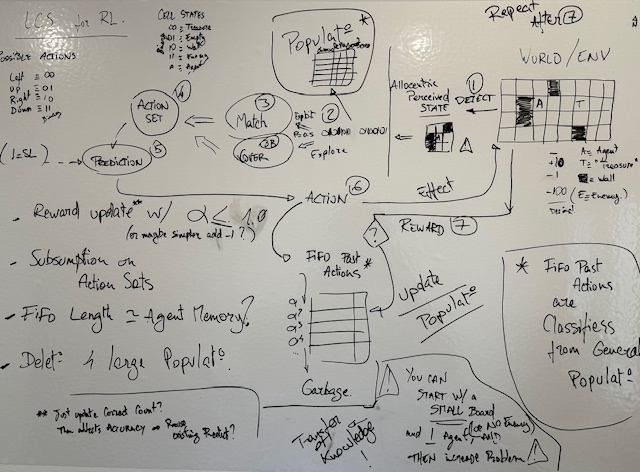
John H. Holland proposed an algorithm with the Cognitive System One program (1976). Later, people came up with variations… Today we focus on Michigan-style LCS.
Binary input: Example
Neural Networks accept numerical input. Currently, RLCS accepts Binary strings.
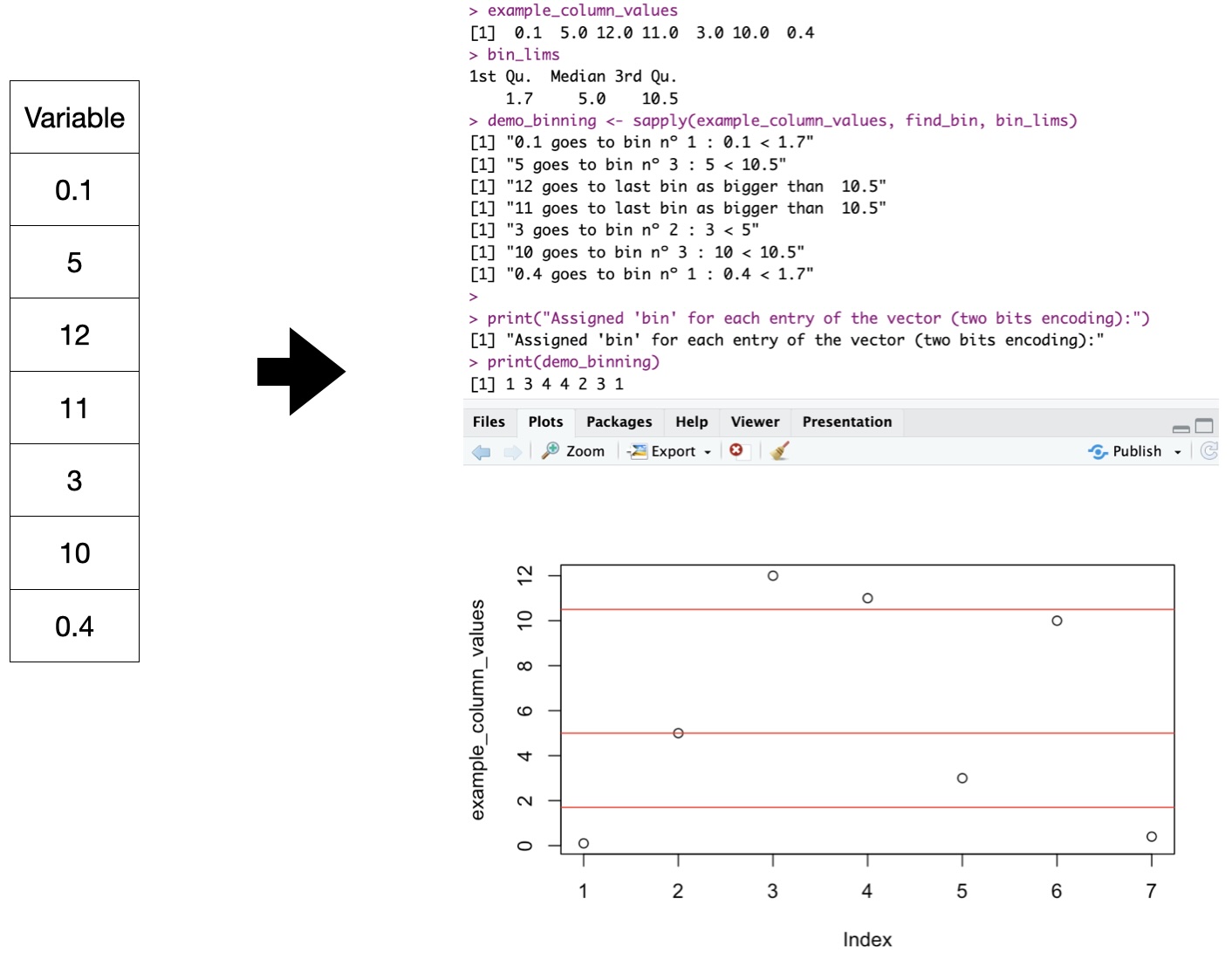
Rosetta Stone “binning” for numerical variables (2 bits explanation)
Supervised Learning: Iris

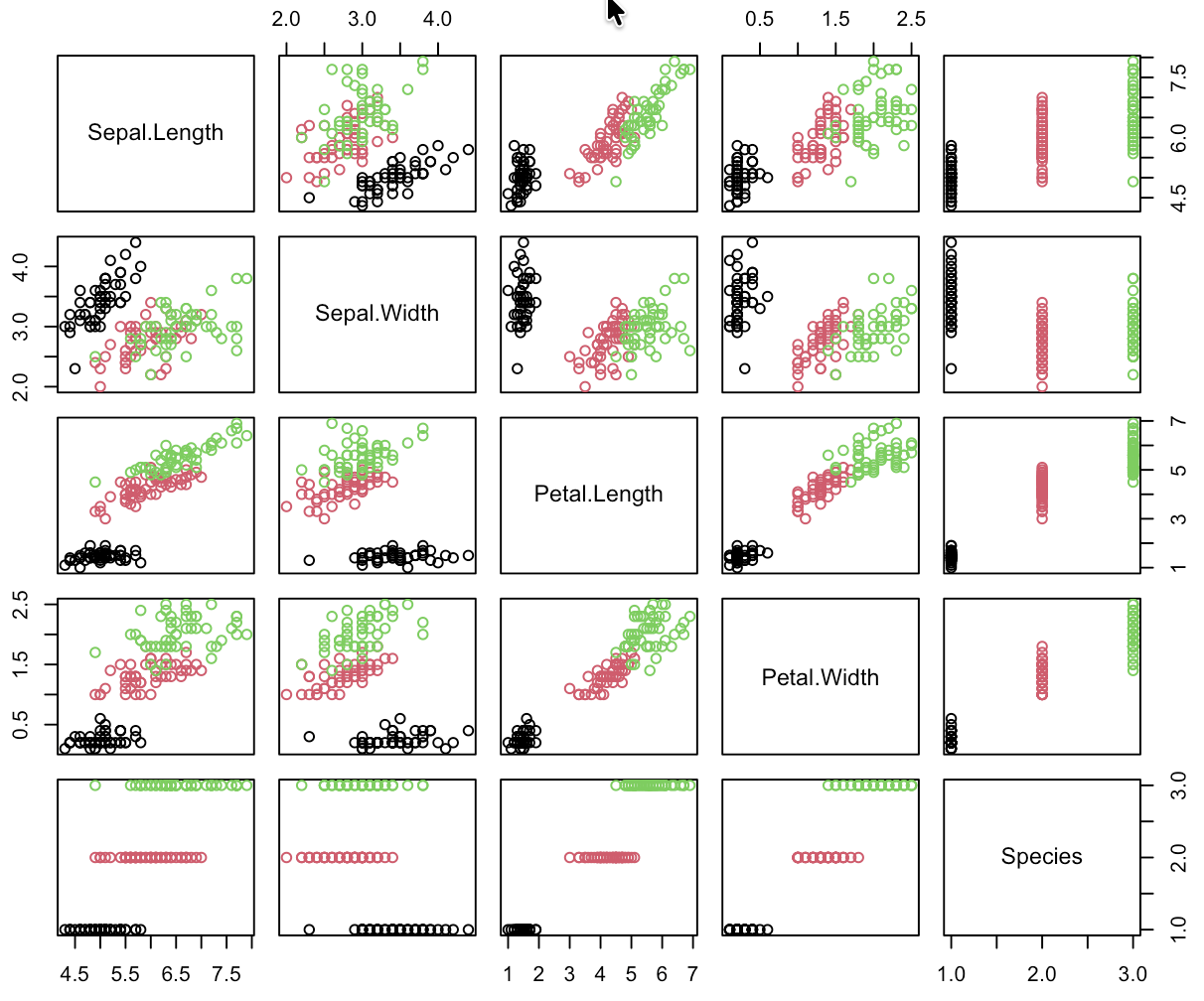
Supervised Learning: Iris
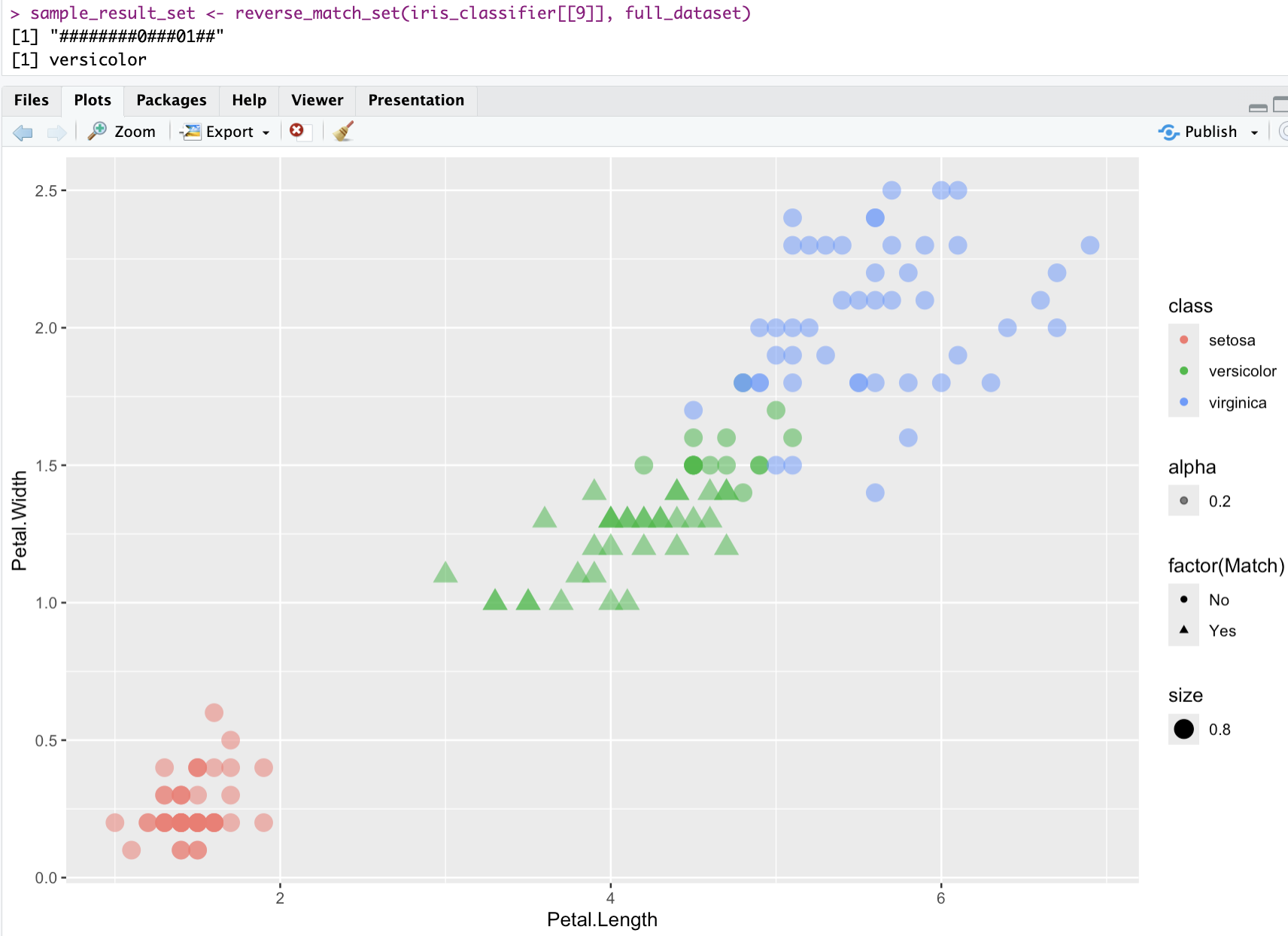
visualizing one classifier - iris
Supervised Learning: Images Classifier

Reinforcement Learning, TOO!
This example is in fact not learning probability distributions. And it uses reward-shaping. But it works!